Portfolio
Full Text Search Engine
Client: Construction Industry Institute
Date: Spring 2022
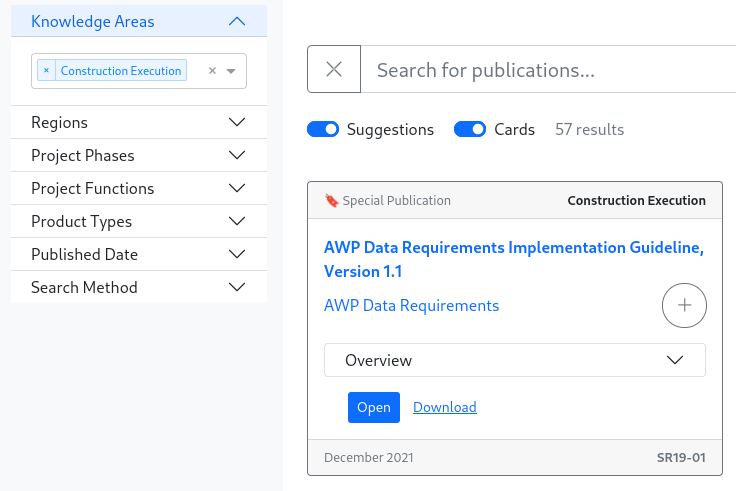
For this project, I was given schema files and ~40 GB of PDFs dating back to the 1970s. My task was to build a full text search engine to allow users to find publications from the contents of their documents (as well as existing metadata).
Over several months, I met with CII and iterated upon the design, optimizing the product to best fit their needs. The authors of the updated Knowledge Base search tool took my web app for inspiration for its layout and features.
Project Details
- Extract tokens from the PDFs (including images).
- Populate the database with text search vectors for the following fields, weighted by importance:
- Document tokens
- Tags
- Title
- Description
- Knowledge Area
- Project Phases
- Project Functions
- Industry Sectors
- Best Practices
- Regions
- Build a web application ("concierge") to allow users to quickly retrieve and interact with publications.
- Preview documents with search tokens highlighted (similar to Google Books).
- Open and Download files, including ZIPs and other file formats.
Technologies Used
Social Media Scraping
Client: Commission on Presidential Debates
Date: Summer 2022
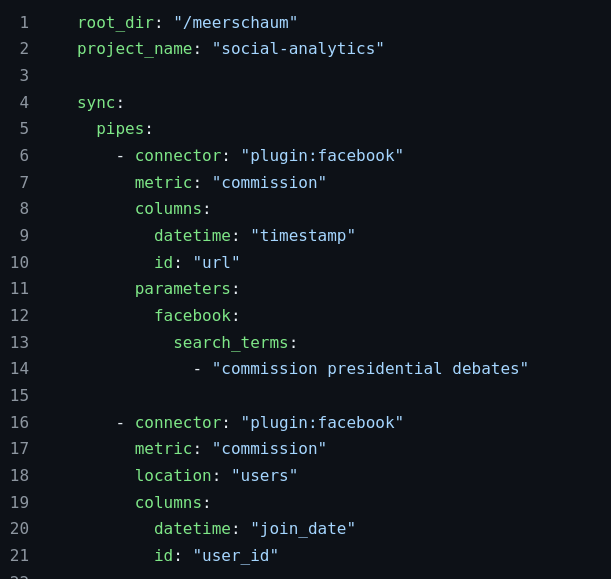
I was approached to scrape several social media websites for comments and messages spreading misinformation (specifically about US elections and other political topics). This project required a short deadline (1 week), so we prioritized four social media websites: Facebook, Telegram, Twitter, and YouTube.
Project Details
For each of the four social media websites, we scraped five months' worth of messages about the Commission on Presidential Debates as well as metadata for each user (join date, profile picture, etc.).
Facebook was perhaps the most difficult website to scrape due to their anti-data-mining measures, such as randomizing the page elements. To obtain the posts, I carefully crafted XPaths and search URLs, then drove the Selenium web driver to continuously scroll and screenshot the page, later processed by OCR. The join date of a user was determined to be the date of a user's first post.
Telegram
I seeded my Telegram scraper with links to about a dozen public channels, then added links to other channels contained in messages. After several iterations, I had over 100 channels to scrape.After scraping the channels for messages from January 2022 through May 2022, I had collected over 1 million messages.
Scraping Twitter was straightforward ― I collected thousands of tweets using the library Scweet.
YouTube
YouTube was the simplest platform of all to fetch data from ― I extracted comments and users using the YouTube data API and the transcripts of the videos using the YouTube transcript API.
Technologies Used
- TimescaleDB
- Selenium
pytesseracttelethon- YouTube data and transcript APIs